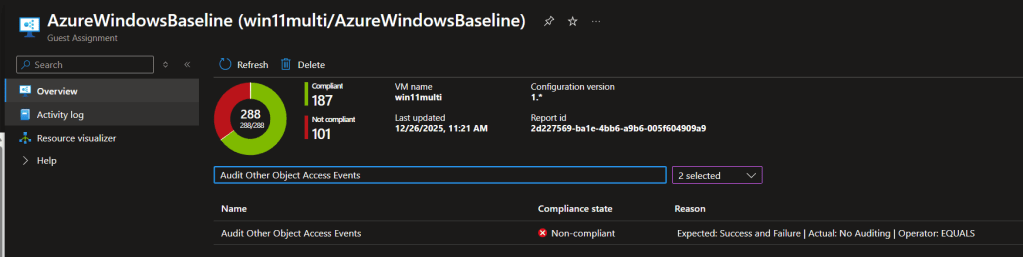
Need to verify which claims Microsoft Entra ID is sending to a SAML application, but cannot install a browser extension? This post shows how to capture the SAML response with Edge Developer Tools, decode it locally with PowerShell, and inspect group claim values safely.
Recently, I needed to confirm whether Microsoft Entra ID was passing a specific group to a SAML application.
The application team wanted to know two things:
- Was the group claim included in the SAML assertion?
- What exact value was Entra sending for the group?
Normally, a SAML browser extension makes this easy. In a managed enterprise environment, especially GCC High, installing browser extensions might be restricted. Rather than requesting an exception just to inspect one authentication flow, I used the browser’s built-in Developer Tools and PowerShell.
This approach lets you:
- Capture the SAML response without installing an extension
- Decode the response locally
- Display every claim in the assertion
- Identify group and role claims
- Resolve group object IDs back to Microsoft Entra group names
- Avoid uploading sensitive authentication data to a public decoding site
How the SAML response is delivered
During SAML sign-in, Microsoft Entra ID issues a SAML response to the application. The response contains an assertion with claims about the signed-in user.
Claims are commonly stored in the SAML AttributeStatement. They can include values such as:
- User principal name
- Email address
- First and last name
- Tenant information
- Application roles
- Group memberships
Microsoft Entra allows administrators to view and customize these claims under the enterprise application’s Attributes & Claims configuration.
The SAML response is typically submitted to the application’s Assertion Consumer Service URL using an HTTP POST. The Base64-encoded assertion appears in a form field named:
SAMLResponse
Our goal is to capture that value before the authentication flow finishes.
Step 1: Review the group claim configuration
Before capturing anything, verify how the application is configured to issue group claims.
In the Microsoft Entra admin center:
- Open Entra ID.
- Select Enterprise applications.
- Select the application.
- Select Single sign-on.
- Select SAML.
- Open Attributes & Claims.
- Locate the group claim.
Microsoft Entra can be configured to include security groups, directory groups, or only groups assigned to the application. The administrator can also choose which value is emitted for each group.
Common group value formats include:
- Entra group object ID
- On-premises
sAMAccountName - Domain-qualified
sAMAccountName - On-premises group SID
- Cloud group display name, in supported configurations
In many configurations, the group value will be the Entra group object ID, which looks like this:
7e308f7c-2e6a-4e50-a2f4-64b56b3e9371
This is important because the application team may be looking for a friendly group name while Entra is actually sending a GUID.
Step 2: Open Edge Developer Tools
I recommend using an InPrivate browser session so that you can perform a clean authentication test.
- Open Microsoft Edge in an InPrivate window.
- Navigate to the application, but do not sign in yet.
- Press F12 to open Developer Tools.
- Select the Network tab.
- Enable Preserve log.
- Select the clear button to remove any existing network activity.
Preserve log is important because SAML sign-in redirects the browser across multiple pages and domains. Without it, the request containing the SAML response may disappear when the browser navigates to the application.
Microsoft’s Edge documentation confirms that the Network tool can preserve requests across page loads and display form data from a request’s Payload tab.
Step 3: Perform the SAML sign-in
With the Network capture running, complete the normal sign-in process.
You can start the authentication flow from either:
- The application’s sign-in page
- The My Apps portal
- The Test single sign-on option in the enterprise application
Microsoft documents the test process under:
Entra ID > Enterprise applications > Application > Single sign-on > Test single sign-on.
After authentication finishes, return to Developer Tools.
Step 4: Find the POST containing SAMLResponse
The Network tab may contain many requests, so filtering the list is helpful.
Enter the following in the Network filter:
method:POST
Look for a POST request going to the application’s Reply URL or Assertion Consumer Service URL. It is often one of the final document requests before the application loads.
Select the request and then open the Payload tab.
Under Form Data, look for:
SAMLResponse
You might also see:
RelayState
RelayState helps the application track where the user should be sent after authentication. It is not the SAML assertion we need to inspect.
Copy only the value associated with SAMLResponse.
The value will be a long Base64 string, similar to:
PHNhbWxwOlJlc3BvbnNlIElEPSJf...
Do not copy the words SAMLResponse= unless you plan to remove them before decoding.
Step 5: Decode the SAML response with PowerShell
Rather than pasting the token into a public website, I decode it locally.
Copy the SAMLResponse value to your clipboard and run the following PowerShell script:
$EncodedResponse = Get-Clipboard -Rawif ([string]::IsNullOrWhiteSpace($EncodedResponse)) { throw "The clipboard is empty. Copy the SAMLResponse value and try again."}$EncodedResponse = $EncodedResponse.Trim()# Remove the field name if SAMLResponse= was included in the copied text.if ($EncodedResponse -match '^\s*SAMLResponse\s*=') { $EncodedResponse = $EncodedResponse -replace '^\s*SAMLResponse\s*=\s*', ''}# Remove surrounding quotes if they were included.$EncodedResponse = $EncodedResponse.Trim('"', "'")# Decode URL-encoded characters.$EncodedResponse = [System.Net.WebUtility]::UrlDecode( $EncodedResponse)# URL decoding can turn Base64 plus signs into spaces.$EncodedResponse = $EncodedResponse -replace '\s', '+'# Restore missing Base64 padding when necessary.switch ($EncodedResponse.Length % 4) { 0 { } 2 { $EncodedResponse += '==' } 3 { $EncodedResponse += '=' } default { throw "The copied value does not appear to be valid Base64." }}try { $SamlBytes = [System.Convert]::FromBase64String( $EncodedResponse ) $SamlXmlText = [System.Text.Encoding]::UTF8.GetString( $SamlBytes ) [xml]$SamlXml = $SamlXmlText}catch { throw "Unable to decode the SAML response. $($_.Exception.Message)"}$OutputPath = Join-Path $env:TEMP 'SamlResponse.xml'$WriterSettings = [System.Xml.XmlWriterSettings]::new()$WriterSettings.Indent = $true$WriterSettings.Encoding = [System.Text.UTF8Encoding]::new($false)$Writer = [System.Xml.XmlWriter]::Create( $OutputPath, $WriterSettings)try { $SamlXml.Save($Writer)}finally { $Writer.Dispose()}Write-Host "Decoded SAML response saved to:"Write-Host $OutputPathnotepad.exe $OutputPath
The decoded response is saved to:
%TEMP%\SamlResponse.xml
If the group you are troubleshooting appears in the XML, Entra is successfully including it in the SAML token.
If the group is not listed, review the group claim settings under:
Enterprise applications > Application name > Single sign-on > Attributes & Claims
This process provides a direct view of the actual SAML assertion without requiring a browser extension or uploading the token to a public decoding website.
Remember to delete the decoded XML file after troubleshooting because it may contain usernames, email addresses, group memberships, tenant identifiers, and authentication information.